Disclaimer first: I’m well aware that this is a very short-sighted disk performance analysis.
I had some stress testing I wanted to do to some new disks prior to putting them into production. Because I’m too poor/cheap to buy SAN adding disks will result in an outage of my services, which means taking them back offline in the event that something was wrong would at least double my outage window, probably more.
In addition to my meager endurance testing I also wanted to do my own analysis of how bad RAIDZ sucks. Don’t get me wrong, I love ZFS, but more than once its performance (or lack thereof) has come back to bite me. That’s why I’m adding disks to my storage system in the first place. With that in mind I created a few different types of zPools and ran Bonnie++ on them. I am starting with 15 146GB 15k RPM SAS disks, directly attached to FreeBSD 10.0. I had 3 different zPools I wanted to test:
- RAIDZ – 5 of 3+1
- RAIDZ – 1 of 14+1 (unrealistic to ever use I know)
- RAID10 – 7 of 1+1
I created a single zPool in each case representing the disk layouts I wanted to compare, I then created a single ZFS inside the disk pool with no tuning, except in the case of those with compression. For those with compression, the zfs option was set to lzjb.The command used to run each test was
bonnie++ -s 81920 -d /pool0/bonnie -n 0 -m diskbench -f -b -u root -x 6
The results of all six rounds of testing:
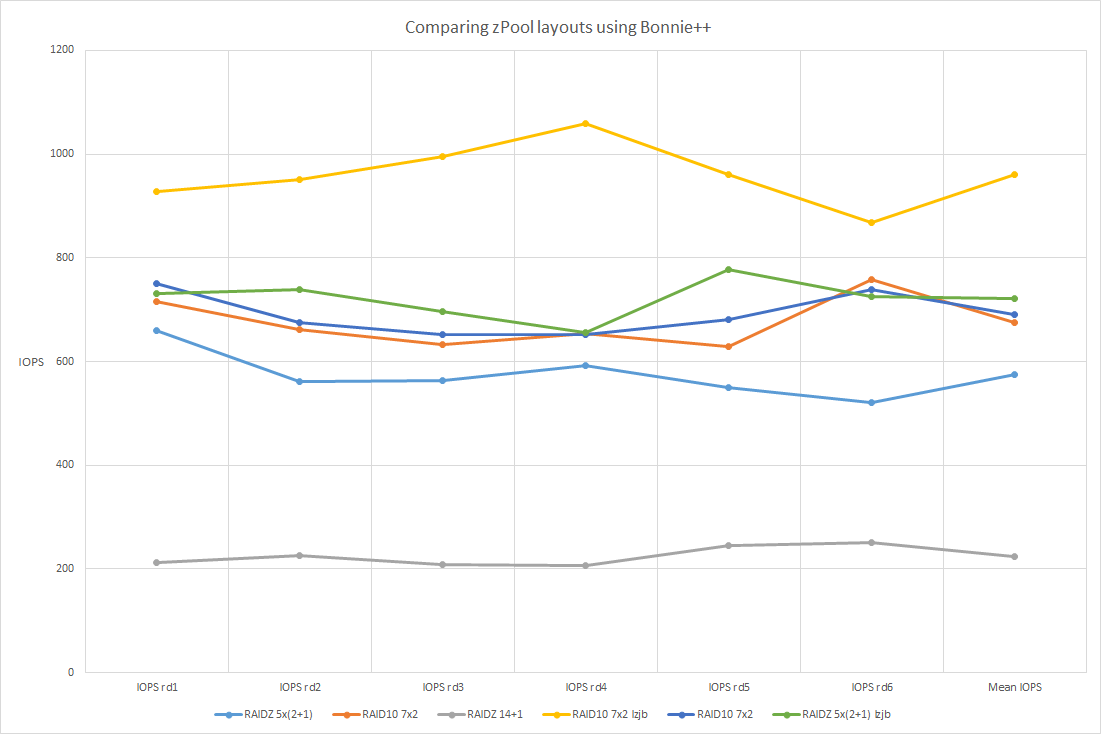
So I was disappointed in that the RAID10 didn’t do terrifically better than the RAIDZ 5 of 2+1. As a matter of fact I may end up choosing the latter model as it gives me over 400GB of additional usable space at minimal cost of redundancy and performance. On the other hand, with the RAID10 configuration I do have a hot spare. It may come down to the toss of a coin. One thing is (and always has been) certain though, and that is that I’ll definitely be compressing the data. It was for that reason, midway through I wanted to enable compression and how the compression vs. non-compression analysis came about. As I said at the beginning of this post the tests are barbaric and take into count no sense of the actual workload that this box will see, and also it will be delivered via NFS to the clients, however at first glance a compressed ZFS volume will outperform an uncompressed volume with this particular setup.
The reason for the additional speed using these barbarian tests is that I go from 80GB of block data to only 2.3GB when compressed. The compression ratio is indeed insane and is no doubt the reason for the increase in speed. At the expense of some leftover CPU cycles (which I have plenty of on my production system) I spend a lot less time going to spinning disk since such a great ratio of my useful data lives in ARC. On my production system, this 80GB test would have never went to disk as all of the compressed data would have been in ARC.
Once I get the disks attached to the production system we’ll run some real world tests where I create a workload somewhat representative of my clients and run IOmeter on a guest VM. The results of that – yet to come.


